
Decoding History: Advancing Text Recognition with HumanAI – GSoC 2024
Advanced OCR with Transformer Models


Introduction
In the digital age, preserving historical documents is paramount for cultural and academic research. Traditional Optical Character Recognition (OCR) tools often struggle with the intricacies of aged manuscripts, especially those from the seventeenth century, which present unique challenges due to handwriting variability, font differences, and document degradation. This project, under the Google Summer of Code (GSoC) initiative, aims to leverage transformer models to develop a state-of-the-art OCR system capable of accurately transcribing historical Spanish texts.
Overview
The primary objective of this project is to create an advanced, transformer-based OCR model tailored for seventeenth-century Spanish documents. This initiative is crucial for preserving these historical documents, enabling researchers to access and analyse them digitally. The project focuses on minimising Character Error Rate (CER) and Word Error Rate (WER) to achieve high accuracy in text extraction.
Printing Irregularities
Historical texts from the 16th and 17th centuries often exhibit printing irregularities due to the limited resources and printing techniques of the time. These irregularities create significant challenges for OCR systems, which must accurately interpret and transcribe text that was printed using inconsistent methods.
Printing Irregularities and Ambiguities
Interchangeable Characters: Characters such as 'u' and 'v', and 'f' and 's' were used interchangeably due to limited availability of type molds. For example, "save" might be printed as "faue," and "success" could appear as "fuccefs."
Tildes and Diacritical Marks: Tildes and other diacritical marks were often used to save space or due to reuse of type molds. For instance, a tilde over 'q' indicates 'ue' follows, and 'ñ' replaces 'nn'.
Old Spellings and Modern Interpretations: The character 'ç' in old texts is equivalent to the modern 'z'. For example, "caçar" would be interpreted as "cazar."
Line End Hyphens: Words split across lines might not always be hyphenated. For example, "example" split at the end of a line might appear as "exam ple."
Addressing Printing Irregularities
To address these irregularities, the OCR model can be trained with a comprehensive strategy including data preparation and model adjustments:
Data Augmentation: Create augmented datasets replicating historical text variations to help the model learn and interpret these variations correctly.
Dictionary-Based Checks: Implement checks against a dictionary to help disambiguate characters based on context.
Model Calibration: Use margin loss and other techniques to ensure the model learns context-specific use of interchangeable characters and diacritical marks.
Regularisation Techniques: Apply cross-entropy and KL divergence losses to maintain a balance between learning the irregularities and adhering to standard language rules.nuances.
Data Preparation
Effective OCR relies heavily on high-quality data preparation. The process began with converting PDFs of historical documents into high-resolution images and splitting them into individual pages. These images were then preprocessed to enhance text recognition, involving steps such as rescaling, binarisation, noise removal, and deskewing. Each line image was paired with its corresponding ground truth text. Given the scarcity of labeled historical data, data augmentation techniques were employed to enhance the dataset and prevent overfitting. These techniques included random rotation, perspective changes, colour adjustments, and the addition of Gaussian noise.
Preprocessing Enhancements
Several preprocessing steps were implemented to further improve the performance of text recognition. These steps included:
Deskewing: Correcting tilted text lines to ensure horizontal alignment.
Noise Removal: Eliminating background noise and unwanted elements such as borders.
Data Augmentation: Mixing processed and unprocessed line images, followed by augmentation, to enhance generalisation.
By combining these preprocessing techniques with robust data augmentation, the model's ability to recognise and transcribe historical text was significantly improved.
Line Segmentation
Accurate line segmentation is crucial as the quality of text recognition significantly depends on this step. The CRAFT (Character Region Awareness for Text detection) model was chosen for its robustness in detecting line-wise bounding boxes. By creating bounding boxes around text lines, CRAFT outperformed other methods like PyTesseract, ensuring that each line segment maintained its integrity. This approach not only improved the accuracy of line detection but also laid a solid foundation for the subsequent text recognition stages.

Model Selection and Architecture
TrOCR Model Overview
The TrOCR (Transformer-based Optical Character Recognition) model stands out for its advanced performance in text recognition tasks, combining the strengths of Vision Transformers (ViT) for image processing with traditional text transformers for sequence prediction. This hybrid architecture is particularly well-suited for the OCR of complex historical documents due to its ability to handle the intricacies of both printed and handwritten text.

[1] : The architecture of TrOCRVision Transformer (ViT) Encoder
The Vision Transformer (ViT) serves as the encoder in the TrOCR model. Unlike traditional Convolutional Neural Networks (CNNs), ViT processes images as sequences of fixed-size patches, treating each patch as a token in a sequence, akin to words in natural language processing.
Patch Embedding: The input image is divided into a grid of patches (e.g., 16x16 pixels). Each patch is then linearly embedded into a fixed-size vector.
Position Embeddings: To maintain the spatial information, position embeddings are added to the patch embeddings, ensuring that the model can understand the order and position of patches within the image.
Transformer Layers: The embedded patches, combined with their position embeddings, are fed into standard transformer layers. These layers consist of multi-head self-attention mechanisms and feed-forward neural networks, enabling the model to capture complex relationships and patterns within the image.
The ViT encoder is pretrained on large image datasets, such as ImageNet, which allows it to learn rich and generalisable visual features.
Text Transformer Decoder
The decoder in the TrOCR model is a transformer-based architecture, typically initialized with a pretrained BERT model. The decoder's primary role is to generate text sequences from the visual features extracted by the encoder.
Input Embedding: The decoder takes token embeddings as input, starting with a special [BOS] (beginning of sequence) token. Each token is embedded into a fixed-size vector.
Positional Encoding: Similar to the encoder, positional encodings are added to the token embeddings to preserve the order of the tokens.
Transformer Layers: The decoder consists of multiple transformer layers, each comprising multi-head self-attention, cross-attention with the encoder's output, and feed-forward neural networks. The self-attention mechanism allows the decoder to focus on different parts of the generated sequence, while the cross-attention mechanism aligns the text tokens with the visual features from the encoder.
The decoder autoregressively generates text tokens by predicting the next token in the sequence until a special [EOS] (end of sequence) token is produced.
Pretrained Model Integration
A significant advantage of the TrOCR model is its use of various pretrained models for both the encoder and the decoder. By leveraging these pretrained models, TrOCR benefits from rich prior knowledge in both visual and textual domains, which is crucial for handling the diverse and complex patterns found in historical documents.
ViT Pretraining: The Vision Transformer encoder is pretrained on large-scale image datasets, enabling it to capture general visual features that are transferable to the OCR task.
BERT Pretraining: The BERT-based decoder is pretrained on extensive text corpora, equipping it with a deep understanding of language structure and semantics.
These pretrained models provide a robust starting point, allowing TrOCR to excel in recognising and transcribing text from images with minimal fine-tuning.
Fine-Tuning
Fine-tuning the TrOCR model for historical Spanish text involved preparing a specialised dataset as explained above. Training the TrOCR model to achieve optimal performance involved a multi-faceted approach that combined careful hyperparameter selection, advanced training techniques, and rigorous evaluation metrics.
Hyperparameter Optimisation
The initial phase of training involved selecting and fine-tuning hyperparameters through empirical experimentation and Bayesian optimisation using Optuna. The primary components of this optimisation process included:
Optimiser: The AdamW optimiser was chosen for its ability to dynamically manage learning rates while applying weight decay to prevent overfitting. This optimiser is particularly well-suited for transformer architectures due to its robust performance in handling sparse gradients and large parameter spaces.
Learning Rate Scheduling: Two types of learning rate schedulers were employed: linear and cosine. The linear scheduler provided a steady decrease in the learning rate, ensuring stable convergence, while the cosine scheduler offered a more gradual adjustment, which is effective in the later stages of training to fine-tune the model’s weights precisely.
Evaluation Metrics: The performance of the model was primarily evaluated using Character Error Rate (CER), Word Error Rate (WER), and BLEU scores. CER and WER quantify the accuracy of text recognition at the character and word levels, respectively, while BLEU scores measure the quality of the text generation by comparing it to reference sequences.
The hyperparameters were iteratively refined to balance the trade-offs between learning rate, batch size, and gradient accumulation steps, ensuring that the model achieved both high accuracy and generalisation.
Training Strategies
The training process was designed to maximise the model’s ability to generalise from the training data while maintaining robustness and stability. Key strategies included:
Multi-GPU Training: Utilising multiple GPUs allowed for larger batch sizes and accelerated training times. This approach enabled the model to process more data simultaneously, improving its generalisation capabilities by exposing it to a diverse range of training examples.
Gradient Accumulation: To effectively manage memory constraints and allow for larger effective batch sizes, gradient accumulation was employed. This technique involved accumulating gradients over several iterations before updating the model parameters, providing a more stable convergence and reducing the likelihood of overfitting.
Early Stopping: Implemented as a safeguard against overfitting, early stopping monitored the evaluation metrics and halted the training process when no significant improvements were observed over a predefined number of epochs. This strategy ensured that the model did not continue to train on data without meaningful gains in performance.
Evaluation Metrics
The model’s performance was rigorously evaluated using CER, WER, and BLEU metrics:
Character Error Rate (CER): CER was computed by dividing the total Levenshtein distance (edit distance) between the predicted text and the ground truth by the total number of characters in the ground truth. This metric provided a granular measure of the model’s precision in recognising individual characters, which is crucial for accurately transcribing historical texts with unique orthographic patterns.
Word Error Rate (WER): WER was calculated similarly to CER but focused on word sequences. It divided the total edit distance between predicted and reference word sequences by the number of words in the reference sequence. WER offered insights into the model’s effectiveness in recognising coherent word sequences, which is essential for maintaining the context and readability of transcribed text.
BLEU Score: The BLEU score was used to evaluate the quality of text generation by comparing the predicted sequences to reference sequences. It measured the overlap of n-grams between the generated text and the reference, providing a comprehensive assessment of the model’s ability to produce fluent and contextually accurate text.
These metrics were continuously monitored throughout the training process, guiding adjustments to hyperparameters and training strategies to ensure the model achieved the highest possible accuracy and robustness.
Advanced Techniques: Model Calibration
In the realm of training conditional language generation models, maximum likelihood estimation (MLE) is the conventional method for assigning probabilities to target sequences based on input contexts. However, models trained with MLE often encounter difficulties in correctly ranking generated sequences by their quality. This can result in suboptimal outputs when utilising decoding strategies such as beam search. The concept of sequence likelihood calibration (SLiC) provides a solution to these issues by enhancing the alignment between model-generated sequences and reference sequences in the model's latent space, thereby improving the quality of generated sequences.
Sequence Likelihood Calibration (SLiC)
Sequence likelihood calibration (SLiC) is a technique that adjusts the probabilities assigned to sequences generated by a model to ensure these probabilities more accurately reflect the quality of the sequences. By aligning the likelihoods of generated sequences with their reference counterparts, SLiC eliminates the need for traditional decoding heuristics and significantly enhances the quality of the generated text across various decoding methods.
Key Components of SLiC:
Decoding Candidates: SLiC begins by decoding multiple candidate sequences from a fine-tuned model using standard decoding methods such as beam search, diverse beam search, or nucleus sampling. These candidate sequences serve as the basis for further calibration.
Similarity Function: The similarity between the model-generated sequences and the target sequence is measured within the model's latent space. This involves extracting the decoder output hidden states and calculating cosine similarities over spans of tokens. These similarities are aggregated using an F-measure-based function, which is akin to BERTScore but utilises the model’s own decoder states for a more integrated approach.
Calibration Loss: Various types of calibration losses are employed to align the sequence likelihoods according to their similarity scores:

Source [3]: Calibration loss

Rank Loss: Optimises the ranking order of positive and negative candidate pairs by ensuring that sequences with higher similarity scores have higher likelihoods.
Margin Loss: Maximises the probability gap between positive and negative candidates, enhancing the distinctiveness of high-quality sequences.
List-wise Rank Loss: Optimises the ranking orders of a list of candidates using a contrastive loss, which is beneficial for handling multiple candidates simultaneously.
Expected Reward Loss: Maximises the expected similarity of a list of candidates, focusing on the overall quality of generated sequences.
Regularisation Loss:

Source [3]: Regularisation loss

To prevent the model from deviating excessively from the original MLE objective, regularisation losses such as cross-entropy and KL divergence are applied:
Cross-Entropy Loss: This is the standard fine-tuning MLE objective that regularises the model towards the gold reference.
KL Divergence Loss: Minimises the probability distribution distance between the calibrated model and the fine-tuned model at each token of the observed target sequence, ensuring smooth adaptation.
Implementation of SLiC in Model Calibration
To implement SLiC in the TrOCR model, several steps and algorithmic choices were made, focusing on margin loss as a primary calibration technique.
1. Similarity Function:
The similarity function was used to calculate the cosine similarity between the representations of candidate sequences and target sequences in the model's latent space. This was achieved by extracting hidden states from the decoder and computing similarities over spans of tokens, aggregated using an F-measure-based function.
2. Calibration with Margin Loss:
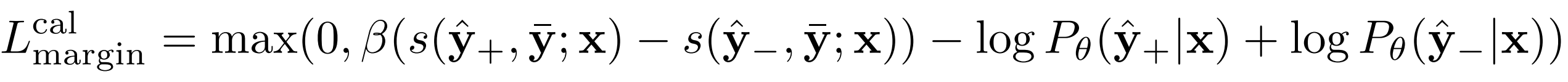
Margin Loss Calculation: Margin loss was chosen to maximise the sequence probability gap between positive (high-quality) and negative (low-quality) candidates. This was achieved by:
Computing log probabilities for each token in the sequence.
Identifying the highest incorrect class logit to ensure the model distinguishes clearly between correct and incorrect sequences.
Calculating the margin loss by clamping the difference between positive and negative candidate similarities, adjusted by a margin parameter.
3. Regularisation Techniques:
Cross-Entropy Loss: The standard cross-entropy loss was used to maintain alignment with the gold reference sequences, ensuring that the model did not deviate excessively from the expected output.
KL Divergence Loss: KL divergence was applied to minimise the distribution distance between the calibrated model and the fine-tuned model, ensuring the calibration process did not disrupt the learned representations significantly.
4. Training Strategy:
The model was first fine-tuned using MLE and then further trained with a combined objective that included the margin loss and regularisation losses. This dual-objective training ensured that the calibrated model produced sequences with higher quality, as measured by their similarity to reference sequences.
Training Steps:
Decoding Candidates: Multiple candidate sequences were generated using methods like beam search and diverse beam search.
Calculating Similarities: For each candidate sequence, the similarity to the target sequence was calculated using the model's latent space representations.
Applying Loss Functions: The calibration loss (margin loss) and regularisation losses were applied to adjust the model's parameters.
Updating Model Parameters: The model was updated iteratively to minimise the combined loss, ensuring better alignment between generated sequences and reference sequences.
By integrating sequence likelihood calibration into the training process, the TrOCR model achieved higher quality text generation, effectively addressing the challenges posed by traditional MLE training and enhancing the overall performance of OCR systems for historical text recognition. This approach not only improved the sequence ranking by quality but also eliminated the need for common decoding heuristics, making the model more efficient and scalable.
Results and Achievements
In a recent evaluation of OCR models fine-tuned on historical Spanish texts from the 16th and 17th centuries, we explored various approaches to improve transcription accuracy. These texts posed significant challenges, featuring complex orthographic variations and physical degradation. To assess the effectiveness of the models, we used two critical metrics: Character Error Rate (CER) and Word Error Rate (WER).

The results revealed a clear hierarchy in performance among the different fine-tuning strategies. The baseline model, trained using Cross Entropy Loss (CE), produced a CER of 0.034 and a WER of 0.100. While applying beam search showed some improvement, yielding a CER of 0.042 and WER of 0.088, the most significant gains came from incorporating margin loss.

A combination of margin loss and cross-entropy regularization further reduced the error rates, achieving a CER of 0.026 and a WER of 0.069. However, the standout performance came from the model fine-tuned solely with margin loss, which produced the lowest error rates across the board: a CER of 0.024 and a WER of 0.047. This underscores the effectiveness of margin loss in enhancing token prediction accuracy and improving sequence ranking in historical document transcription.

Final Tool
This tool allows users to process scanned PDFs, apply advanced line segmentation using CRAFT, and extract text using fine-tuned model. It supports automatic deskewing, border removal, and noise reduction for better results. Users can toggle line segmentation, visualize bounding boxes, and perform OCR to extract text line by line, ensuring accurate document digitization. Ideal for digitizing books, articles, and any other multi-page documents. The tool also allows saving processed pages and provides real-time feedback during the OCR process.
Conclusion
In conclusion, this project successfully developed a cutting-edge OCR system using the TrOCR model, achieving remarkable improvements in transcription accuracy for historical Spanish texts. Through advanced techniques like margin loss, hyperparameter optimization, and model calibration, the tool significantly reduced Character Error Rate (CER) and Word Error Rate (WER), making it a powerful resource for digitizing and preserving historical documents. This accomplishment not only demonstrates the potential of transformer-based models in OCR but also provides an essential tool for researchers and archivists, fostering further innovation in cultural heritage preservation. For those interested in exploring the implementation and contributing further, the code is available on GitHub: Utsav Rai's Transformer OCR.
You can also find more details about this project on the GSoC platform: GSoC 2024 Project.
By sharing the code, we hope to foster collaboration and innovation in the field, ultimately improving the tools available for preserving and studying historical documents.
References
Li M, Lv T, Chen J, Cui L, Lu Y, Florencio D, Zhang C, Li Z, Wei F. Trocr: Transformer-based optical character recognition with pre-trained models. InProceedings of the AAAI Conference on Artificial Intelligence 2023 Jun 26 (Vol. 37, No. 11, pp. 13094-13102).
Baek Y, Lee B, Han D, Yun S, Lee H. Character region awareness for text detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition 2019 (pp. 9365-9374).
Zhao Y, Khalman M, Joshi R, Narayan S, Saleh M, Liu PJ. Calibrating sequence likelihood improves conditional language generation. InThe eleventh international conference on learning representations 2022 Sep 30.